
EHDS interoperability gave clinicians access to cross-border health data. Making that data usable at the point of care is a different problem entirely.
As health data begins to flow more freely across Europe, attention is shifting from exchange to usability. This article explores the gap between retrieving information and making clinical sense of it, and why many experts see conversational interoperability as the next layer needed to turn EHDS access into practical clinical value.
1. What does it actually take to make EHDS useful at the point of care?
Access was always the first problem to solve, and EHDS solved it. Twenty-seven jurisdictions aligned on a common API surface, a defined Patient Summary, and consent and identity flows that work across borders. For the first time, a clinician in Germany has a legal and technical path to retrieve a patient record from the Netherlands, France, or Slovenia without a custom integration project on either end. That is not a small thing, and it did not happen quickly.
The transport works. That is worth saying clearly, because it took a long time and it matters enormously for what comes next. What it did not solve is what happens after the data arrives.
Access and usability are different problems, and EHDS was only ever designed to solve the first one.
An accurate picture of what cross-border healthcare data looks like when it actually flows, is this; seven structured patient summaries (one current, two superseded), three discharge letters in three languages, an overlapping medication list with three different formulations of what may or may not be the same anticoagulant, and a problem list whose codes don’t quite line up between countries.
And somewhere behind that screen is a clinician with four minutes, a patient with chest pain and an irregular pulse, and no clean way to form a single coherent picture from what the system just handed the clinician. The clinician has access, but what he or she needs is time.
Those are different problems, and only one of them has been solved. Conversational interoperability is what addresses the second one.
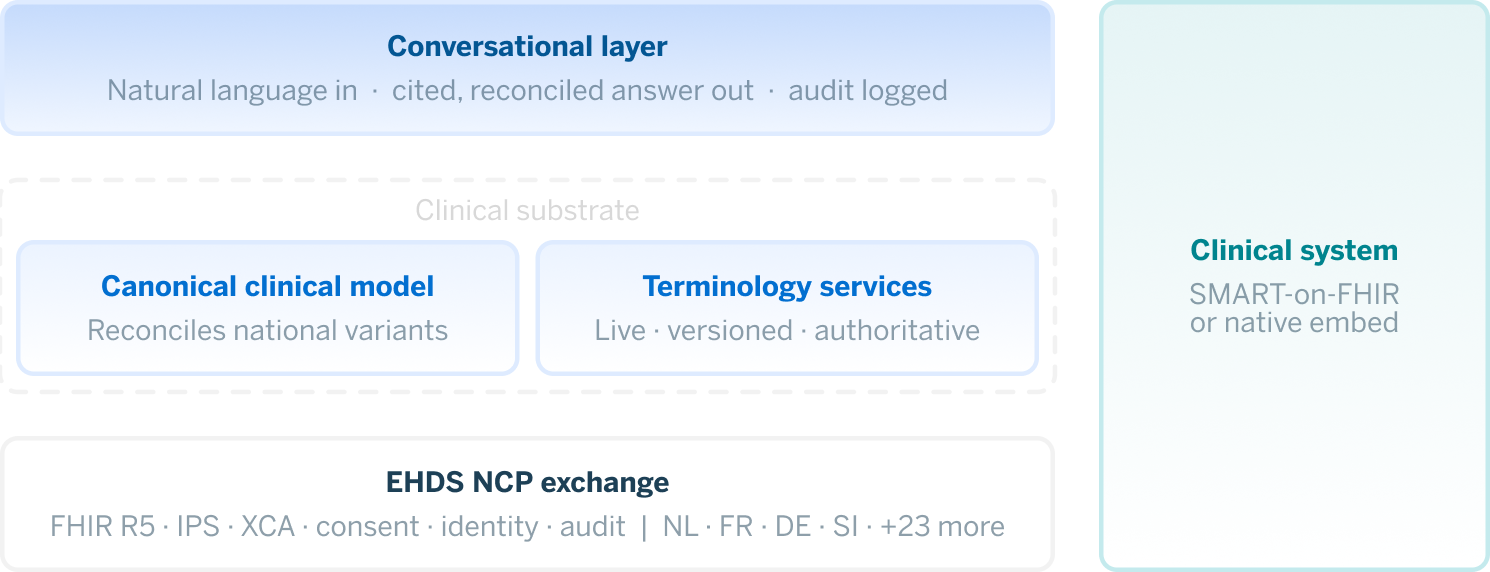
2. How EHDS enables cross-border health data exchange
It’s worth being precise about EHDS, because any “what comes next” piece risks treating the predecessor as mere prologue. EHDS is the mandatory base on which everything else stands. EHDS established cross-border exchange of electronic health data as a legal default across the EU. It set the APIs, mandated the profiles, and defined the Patient Summary as the baseline structured artefact, requiring member states to expose it through their National Contact Points. Consent, identity, and the legal basis for cross-border retrieval now sit on a footing that twenty-seven jurisdictions can operate against.
Think of it as what FHIR was for clinical data exchange a decade ago: a transport layer that the field has rallied around, that works, and that everything else will be built on top of.
Conversational interoperability across borders is not possible without EHDS.
Without standardised cross-border APIs, every national system remains a custom integration. Without IPS as a baseline structured profile, an agent is reasoning over arbitrary national document formats. Without the consent and identity flow EHDS established, no one can lawfully retrieve another country’s data on a patient’s behalf in the first place. EHDS made the conversation legally and technically possible. The next piece of work makes it useful at the bedside.
3. The remaining challenges of EHDS interoperability
Three problems remain on the consumer side of the EHDS data flow, and they all land on the clinician:
- Reconciliation. When seven Patient Summaries from three countries do not agree on every detail, medications appear with overlapping codings, national variants of the same active substance, and different dosing formats, the clinician must figure out what’s true. And he must do it from a stack of partially overlapping documents, by hand, under time pressure.
- Translation. Even with terminology services and ConceptMaps doing real work behind the scenes, the lived experience of reading a French discharge letter, a Dutch problem list, and a Slovenian operative note is one of constant micro-translation. The clinician becomes a human interpreter running between three half-understood records, where being slightly wrong about what a phrase means can genuinely matter.
- Search. The question that matters in the Berlin ED, whether this patient has ever had atrial fibrillation, anywhere, in any letter, in any country, does not map to a button or a tab. It maps to a search across structured and unstructured content in multiple languages, performed under time pressure. In practice today, the clinician searches by hand or assumes the answer is no.
None of these are EHDS bugs, as the regulation was never meant to solve them. They are simply the next problem, and conversational interoperability is what addresses them.
4. What conversational interoperability means in healthcare
The term has been circulating in the field for a while now, in different forms and with different emphasis. Mark Kramer and May Terry, writing on Language-First Interoperability in 2025, framed the core problem this way: before any meaningful data sharing can happen under current standards-based approaches, everyone must agree in advance on exactly how the data will be structured, write detailed implementation guides, and spend months or years getting everything aligned. Their proposal was that AI agents could negotiate that coordination in natural language in real time, replacing the pre-coordination step without replacing the standards themselves.
Tom Varghese at Orion Health has extended the concept under the name COIN, Conversational Interoperability Network, framing it as natural-language interaction as a first-class mode of healthcare data access, built on top of FHIR rather than around it.
What both framings share is the same underlying observation: the bottleneck in healthcare data exchange has always been at the human layer, not the technical one. Standards and pipes exist. What is slow, error-prone, and expensive is the work humans do to make sense of what comes through those pipes. Conversational interoperability moves that work from human to the system.
In the EHDS context, it looks like this. The German clinician asks, in German: “what is she currently taking?”
Behind the scenes, IPS documents are retrieved from the three NCPs through the EHDS exchange, normalised into a canonical clinical representation, with national terminology variants reconciled against shared ConceptMaps. An agent grounded in that canonical record resolves the medications across all three sources, validates the codings, and renders active substances in the clinician’s preferred language. Each fact carries a citation back to its source. On screen, within two seconds:
Five active medications, last reconciled across NL · FR · SI on Thursday. Apixaban 5mg b.d. (FR, prescribed 2023-09). Bisoprolol 5mg o.d. (SI, prescribed 2025-06). Atorvastatin 40mg o.d. (NL, prescribed 2024-11). Metformin 1g b.d. (NL, prescribed 2024-11). Pantoprazole 40mg o.d. (FR, prescribed 2023-09). One discrepancy: the Dutch list shows Apixaban at 2.5mg b.d.; the most recent French prescription is 5mg. Worth checking renal function, since 2.5mg b.d. is a recognised renal-adjustment dose.
Every retrieval is logged, consent is bound to the session, and audit trail is intact.

The clinician asks the next question, reaching clinical decision-making in minutes, not in the chart-reconciliation hour she would otherwise have spent. That is what conversational interoperability completes in the EHDS context: not a new interface, but a new relationship between the clinician and the data EHDS made reachable.
5. What has to be true for this to actually work
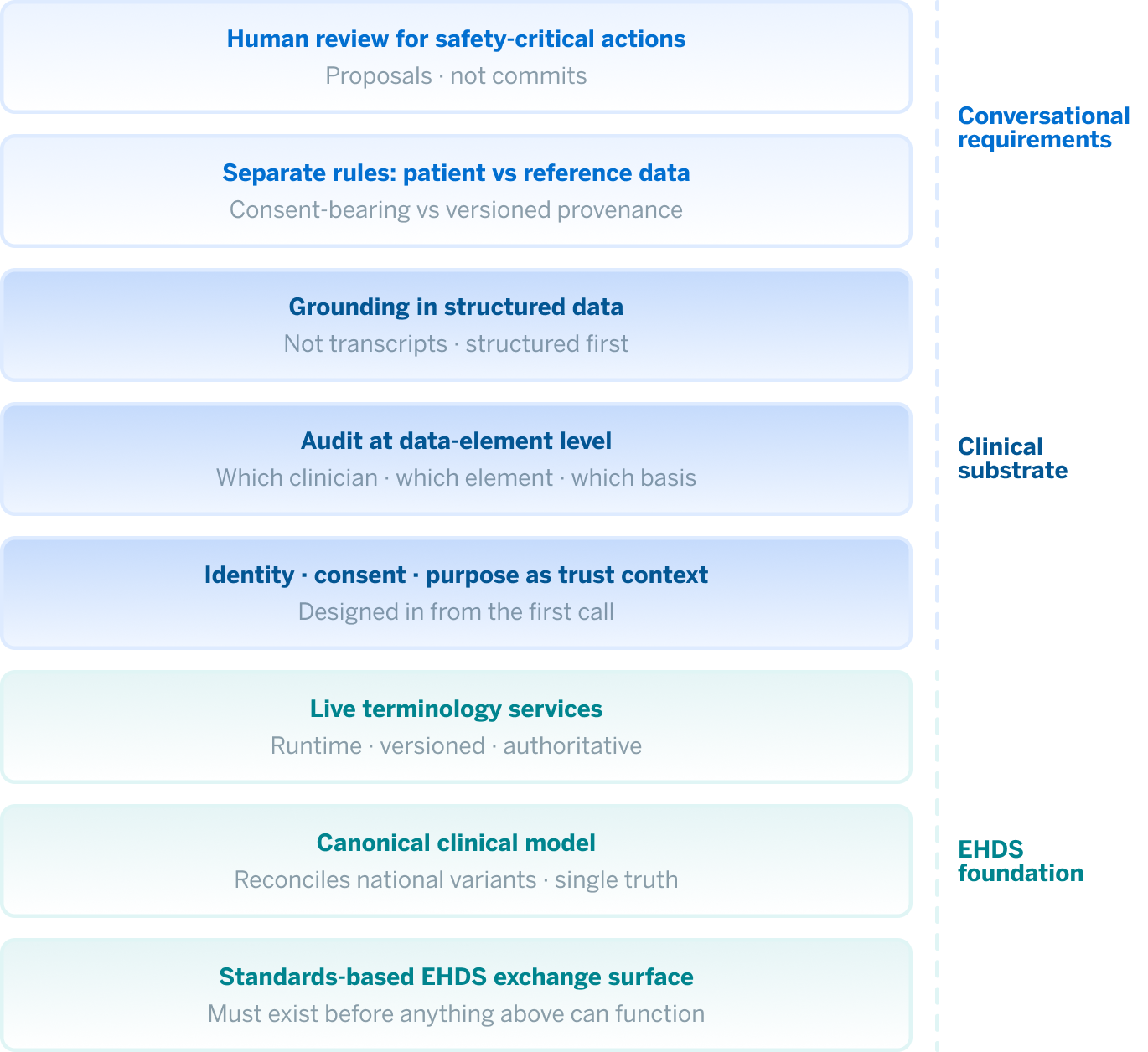
It is tempting to gesture at “AI plus EHDS” and assume the rest follows. It does not. There are 8 basic prerequisites that must be met, and most of the domain is still working through them.
1. A standards-based exchange surface
This is what EHDS provides. Without it, every country is a custom integration, and every National Contract Point (NCP) is a one-off. With it, the conversational layer can assume a baseline contract: Patient Summary as a defined profile, FHIR as the transport, NCP-to-NCP retrieval as the operational pattern.
2. A reference clinical model
Data returning from three countries will not agree with itself. It needs a place to land, a representation that preserves clinical meaning across national variants and source-system quirks. Without a clear clinical model, an agent reasons over inconsistent inputs and the inconsistency compounds, rather than resolves.
3. Live terminology services
Terminology services is not a one-time data preparation step, but something the conversational layer can call at runtime, query for translations and validations, and get authoritative answers from. It needs to be versioned, fast, and trusted. Much of what goes wrong with healthcare AI goes wrong here: codes translated approximately, value sets out of date, and the agent confidently returning the wrong thing.
4. Identity, consent, and purpose-of-use as a single trust context
Cross-border retrieval is the highest-stakes consent scenario in healthcare interoperability. Every retrieval must be attributable to a clinician, have a purpose (treatment, research, or public health), be justified by a legal basis, and be recorded. It has to be designed in from the beginning, and not added later.
5. Audit at the data-element level
Audit must be available at the level of which clinician asked which question, against which patient’s record, retrieved which data elements, under which legal basis, and with what outcome. This is what regulators will ask for and, more importantly, what clinical safety officers need when something goes wrong.
6. Grounding in structured data, not transcripts
Conversational AI grounded in unstructured chart text hallucinates clinical content. The solution is not a smarter model; it is grounding the agent in the substrate where clinical truth actually lives, which is structured data, and free text can serve as supporting context.
7. Different rules for patient data and reference data
Patient data is consent-bearing and audit-logged at the individual level. Reference data, such as terminologies, drug knowledge, and clinical guidelines, is shared, cacheable, and governed through versioning and provenance. Treating them the same is one of the easier mistakes to make in architecture and one of the harder ones to reverse later.
8. Human review for anything clinical-safety-critical
A conversational layer that retrieves and summarises is one thing. One that places orders, prescribes, or records clinical decisions is an entirely different category. It must surface outputs as proposals that the clinician confirms, not as actions they have to undo. If this is done right, the system can be an aid, but done wrong, it can be a liability.
Together, these components form what we might call the clinical substrate: the governed, structured foundation on which a conversational layer can actually stand. It is worth naming it, because the substrate is what the next question depends on.
Once stated, most of these points would be obvious to any senior architect in clinical informatics. The obvious things, though, are precisely what gets skipped when a vendor demoes a chatbot over a Patient Summary. The gap between a working demo and a deployable system lives in this list.
6. Why does the model become a smaller question
Something interesting follows once you get the prerequisites right.
When the substrate is doing real work, when a reference clinical model is reconciling national variants, when live terminology services are handling code translation, and when grounding is in structured data with citations rather than raw chart text, the heavy work moves out of the model and into the architecture. What the language model is left with is mostly language: understanding what the clinician asked, generating a clear answer, and working in the clinician’s preferred language. Important work, but a much narrower job than what transcript-grounded systems hand to their models.
Transcript-grounded conversational AI in healthcare needs frontier models because it asks the model to do clinical reasoning, terminology lookup, reconciliation, and fluent generation all at once, with no help from the substrate beneath it. Substrate-grounded conversational interoperability asks the model for structured input and clear cited answer. A much wider class of models can do that well, including smaller open-weight models, EU-resident models, and self-hosted deployments.
Frontier models go from being a structural requirement to being a choice. That is a significant difference for any buyer with data residency obligations.
For EHDS interoperability specifically, this is not just a technical detail, it is a sovereignty and procurement consequence. A cross-border European system where data residency, supply-chain risk, and confidentiality are first-order concerns cannot quietly assume that every conversational query will be routed to a single US-hosted frontier model. Some buyers will not permit it, some jurisdictions cannot, and some scenarios in paediatrics, mental health, and sensitive research cohorts will demand a different posture.
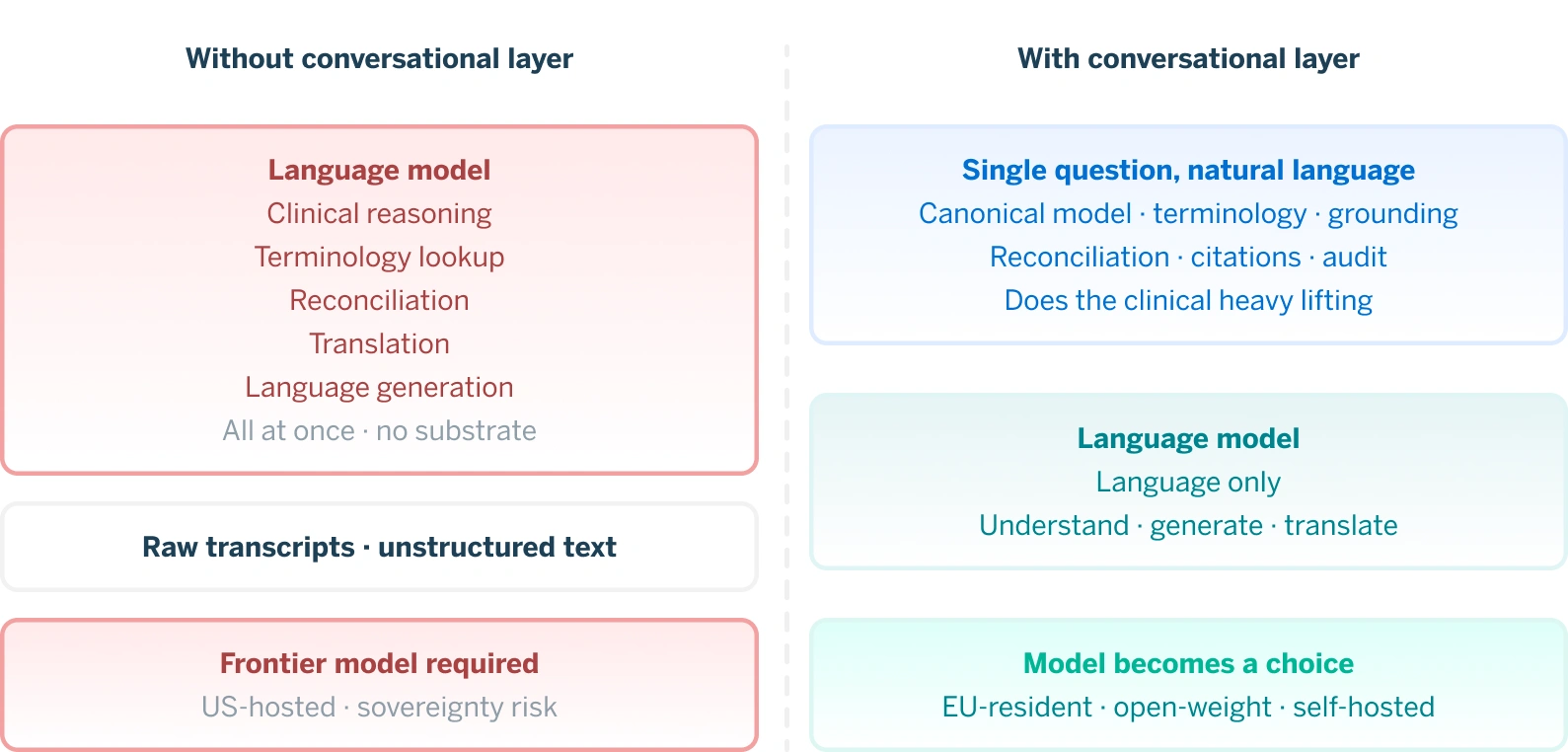
An architecture that lets the model be chosen rather than assumed gives those buyers a viable path. Frontier models still help where they genuinely help, in long context, edge-case reasoning, and polished multilingual generation. They go from being a structural requirement to being a choice, and that distinction matters enormously to the buyers who have data sovereignty obligations they must honor.
7. Why is this the right shape for EHDS
The architectural properties above are what the EHDS context specifically demands.
Vendor neutrality is non-optional, EHDS is multi-national by definition. With twenty-seven jurisdictions, hundreds of source systems, and dozens of NCP implementations, a conversational layer locked to one vendor’s data model cannot serve EHDS. The base must be vendor neutral.
The trust contract is the deployable difference. Most of what goes wrong with healthcare AI in production goes wrong here. A model that produces a plausible answer is easy to build, but a system that produces an answer for this clinician, about this patient, for this stated purpose, with full accountability, is hard. The hard part is what makes a system deployable in regulated cross-border settings.
Semantic grounding is the difference between an aid and a liability. Conversational interoperability must be built on top of structured, canonical data, not on top of transcripts or raw chart text.
8. Where the field is
EHDS is in active deployment, National Contact Points are operational across the early-active jurisdictions, Patient Summary retrieval works, and the foundations for cross-border exchange are becoming real across Europe
Conversational interoperability, the layer that helps clinicians make practical use of that information, is at an earlier stage. But this is no longer a theoretical discussion. The technical building blocks are increasingly understood: structured and governed data, semantic consistency, terminology services, clear trust mechanisms, auditability, and systems designed around clinical workflows.
Different countries, vendors, and national programmes will move at different speeds, and approaches will vary, but the direction is becoming clearer. The challenge is shifting from “Can this work?” to “How do we implement it safely, reliably, and in ways that genuinely help clinicians?”
For organisations thinking about this now, the priority is not starting with a conversational interface, it is getting the foundations right: trusted data, consistent semantics, clear governance, and architectures that support clinical safety from the beginning.
The first step was EHDS making cross-border health data accessible. The next step is making that information easier to use in clinical time, helping clinicians understand what matters, faster, while preserving trust, accountability, and context.
Conversational interoperability is one possible way of doing that. Not by replacing EHDS, but by building on the foundation it created.
For a broader look at the foundations, timelines, and implementation challenges shaping EHDS readiness across Europe, explore our EHDS implementation readiness report.
References and further reading
1. Kramer M., Terry M. “Language-First Interoperability: Exchanging Data Faster Using Real-Time Agent-Based Coordination.” Medium, Jun 2025. medium.com/@kramermark/language-first-interoperability-f650abfb7353
2. Kramer M. “Why Conversational Interoperability is Essential for the Future.” LinkedIn Pulse. linkedin.com/pulse/why-conversational-interoperability-essential-future-mark-kramer-retre/
3. Kramer M. “Birth of a New Interoperability.” LinkedIn, 2025. linkedin.com/posts/mark-kramer-7b0215
4. Varghese T. “What Is COIN in Healthcare Interoperability?” Orion Health, Mar 2026. orionhealth.com/global/blog/what-is-coin-in-healthcare-interoperability/
5. “Language-First Interoperability in Healthcare.” TechMagic, 2025. techmagic.co/blog/language-first-interoperability
FAQ
What is conversational interoperability in healthcare?
Conversational interoperability is the ability to interact with clinical information through natural language while preserving the underlying structure, provenance, and meaning of the data. Rather than replacing existing interoperability standards such as EHDS, FHIR, or openEHR, it builds on them to help clinicians retrieve, understand, and act on information more efficiently at the point of care.
How does conversational interoperability support EHDS?
EHDS enables the exchange of health information across European healthcare systems. Conversational interoperability addresses a different challenge: helping clinicians make practical use of that information once it has been retrieved. By providing context-aware access to patient data, it can reduce information overload and support faster clinical decision-making while maintaining transparency and auditability.
Is access to cross-border health data enough for EHDS success?
No. Access is only the first step. For EHDS to deliver meaningful clinical value, healthcare professionals must also be able to understand, reconcile, and use information originating from different systems, countries, and languages. This requires strong foundations in data quality, terminology management, governance, trust, and clinical usability.
What foundations are required for conversational interoperability?
Conversational interoperability depends on the same foundations that support successful EHDS implementation: structured and governed data, semantic consistency, terminology services, clear accountability, trust mechanisms, and robust interoperability standards. Without these foundations, conversational interfaces risk producing unreliable or clinically unsafe results.