
AI assistants are becoming increasingly capable at understanding natural language, but clinical coding quickly exposes their limits. Grounding agents to FHIR Terminology Services using the Model Context Protocol (MCP) enables precise, verifiable answers instead of confident hallucinations.
Why clinical coding is a hard test for AI
Clinical coding is an unforgiving use case for AI. Unlike conversational tasks, it requires returning exact identifiers from internationally controlled vocabularies such as SNOMED CT, ICD-10, LOINC or specific national or hospital level classifications.
Many teams experimenting with generic large language models (LLMs) encounter the same issue: the model produces answers that look confident and plausible, but fail basic validation. Codes may be outdated, incomplete, or simply not part of the terminology at all. In healthcare, this is not a cosmetic problem, it can break workflows, lead to wrong dispensing of medications, invalidate reports, and cause billing or reimbursement errors.
This behaviour is not a flaw of any single model. Ungrounded LLMs have no authoritative source of truth and no built-in way to verify their output. They are optimised to produce likely text, not validated clinical facts.
Global standards are only part of the picture
For widely used terminologies such as ICD10 and LOINC, tooling and examples are relatively easy to find. As a result, AI systems may appear to perform reasonably well on these vocabularies. But real clinical environments are far more complex. Beyond international standards, every healthcare system depends on national and local coding systems for diagnosing, prescribing, billing, and reporting. They represent critical infrastructure, yet almost invisible to generic AI models. This is not a problem unique to any country in particular; it is a structural reality of global healthcare. Consider a few examples:
- Germany uses OPS (Operationen- und Prozedurenschlüssel) for procedure coding alongside ICD-10-GM, a nationally modified version of ICD-10.
- France maintains the CCAM (Classification Commune des Actes Médicaux) for medical procedures and CIM-10 as its ICD-10 adaptation.
- Australia uses ICD-10-AM and ACHI (Australian Classification of Health Interventions) alongside AMT (Australian Medicines Terminology) for drugs.
- Slovenia operates national terminologies including MKB-10-AM (Slovenian ICD-10 adaptation), CBZ (national drug database), KTDP (therapeutic and diagnostic procedures), and VZS (healthcare service types for referrals and scheduling) – all maintained by the National Institute of Public Health (NIJZ).
For AI agents relying on training data alone, these systems are an essentially unknown territory and even where some coverage exists, the data is almost certainly outdated. The good news is that for many of these terminologies, an authoritative source with standard interface is available: a FHIR Terminology Server. The challenge is connecting AI systems to it reliably.
FHIR Terminology Services in one minute
FHIR (Fast Healthcare Interoperability Resources) Terminology Services provide a standardised REST API for working with clinical vocabularies. Two concepts are central:
- CodeSystems define complete sets of codes and their meanings – for example, all active SNOMED CT concepts or all valid ICD-10-AM diagnosis codes.
- ValueSets define curated subsets of codes for specific clinical contexts – for example, the drug codes relevant for a particular formulary, or valid procedure codes for a given specialty.
Through this API, clients can list available terminologies, search for concepts, expand ValueSets into constituent codes, and validate whether a code is currently active. These are exactly the operations needed to move AI-driven clinical coding from probabilistic guessing to deterministic querying. Importantly, FHIR is an open standard – there is no vendor lock-in. Any FHIR-compliant terminology server can serve as the authoritative source, whether national, institutional, or commercial.
From guessing to grounded answers
Once an authoritative terminology server is available, the design principle is straightforward: query the server and treat its response as the source of truth. The model understands the question and communicates the answer in natural language, where the factual content, the actual codes, is retrieved from the server rather than generated from LLM internal knowledge based on training data. This fundamentally changes the failure mode. Instead of a plausible-but-wrong code, a grounded agent can report explicitly: “no valid code was found”, or “the submitted code is deprecated”. Transparent failure is far safer than silent fabrication. The remaining question is architectural: how do you connect an AI agent to terminology services reliably, without hardcoding logic into prompts?
Model Context Protocol (MCP)
The Model Context Protocol (MCP) addresses this integration problem. MCP standardises how external tools and services are discovered and invoked by AI agents. Rather than generating an answer from LLM internal knowledge based on training data, the agent uses MCP to call well-defined operations on external systems, receive structured results, and incorporate those results into its response.
The split of responsibility is measured. The LLM is restricted to natural language intent parsing, and a MCP server enforces a closed tool environment, allowing access solely to FHIR terminology operations. Every response is deterministically derived from the terminology service. If a concept is absent from the underlying CodeSystem or ValueSet, the agent is unable to fabricate an answer.
Introducing the FHIR Terminology MCP Server
At Better, we have built an MCP server that exposes FHIR terminology operations as a set of narrowly defined tools. The model handles intent and orchestration, the terminology server enforces correctness. When a user asks “What is the CBZ code for ibuprofen?“, the agent calls the appropriate MCP tool, queries the CBZ ValueSet on the connected FHIR server, and returns exactly what is there.
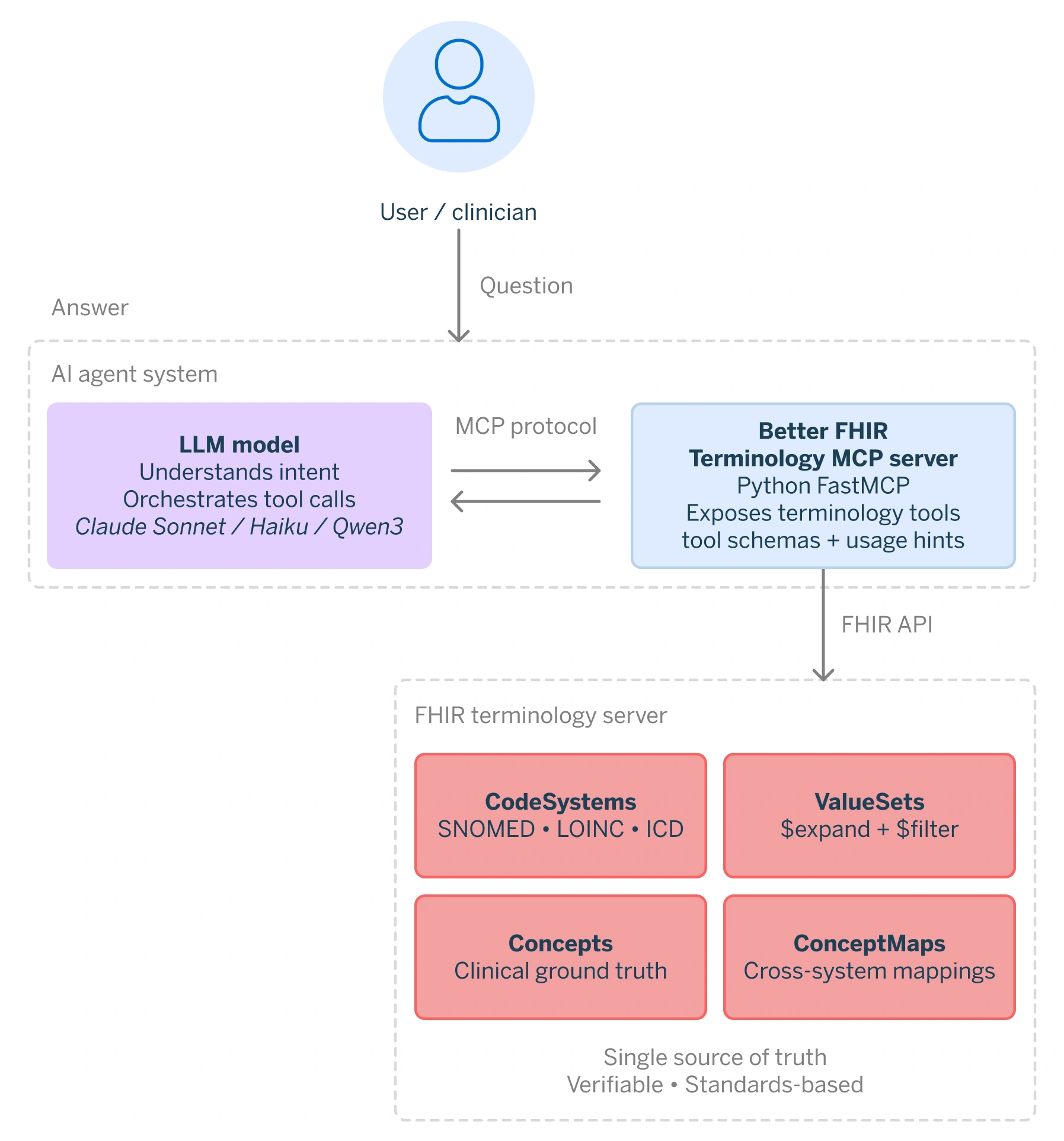
This architecture has several important properties:
- Deterministic answers: Every response is derived directly from the terminology service. If a concept is absent from the CodeSystem or ValueSet, the agent says so explicitly, rather than fabricating a plausible-looking answer.
- Auditability: Every code returned is traceable to a specific CodeSystem version on a specific server at the time of the query. If a result is ever questioned, the source is unambiguous – a property that matters greatly in regulated healthcare environments.
- No fine-tuning is required: All terminology-specific capability lives in the MCP server – tool definitions, query patterns, and domain logic. The agent itself needs no special training for clinical coding. Even smaller, locally hosted models perform well when the task scope is tightly constrained by the tool environment.
- Portable expertise: The domain knowledge travels with the server, not the model. Connecting the MCP server to a different agent or orchestration framework is straightforward, with no rework of the clinical logic.
- No vendor lock-in: Because FHIR is an open standard, the MCP server can be pointed at any FHIR-compliant terminology server – national, hospital-level, or commercial – and the agent’s behaviour adapts accordingly.
Concrete examples
The following examples cover four capabilities: discovering the connected terminology server, looking up drug codes, querying hierarchical SNOMED CT relationships, and validating a national code. Each one is grounded in live data from the FHIR Terminology Service, not generated from model memory.
Discovering available terminologies
A natural starting point is asking which terminology server the agent is connected to and what CodeSystems it exposes. Because FHIR is an open standard, the MCP server can be pointed at any compliant terminology server – national, institutional, or commercial – and switched at any time without changing the agent or its tools. The agent dynamically discovers what is available on the connected server rather than relying on hardcoded assumptions. In the example below, the query returns both international standards and national Slovenian terminologies published by NIJZ.

Looking up drug codes: ibuprofen in the CBZ
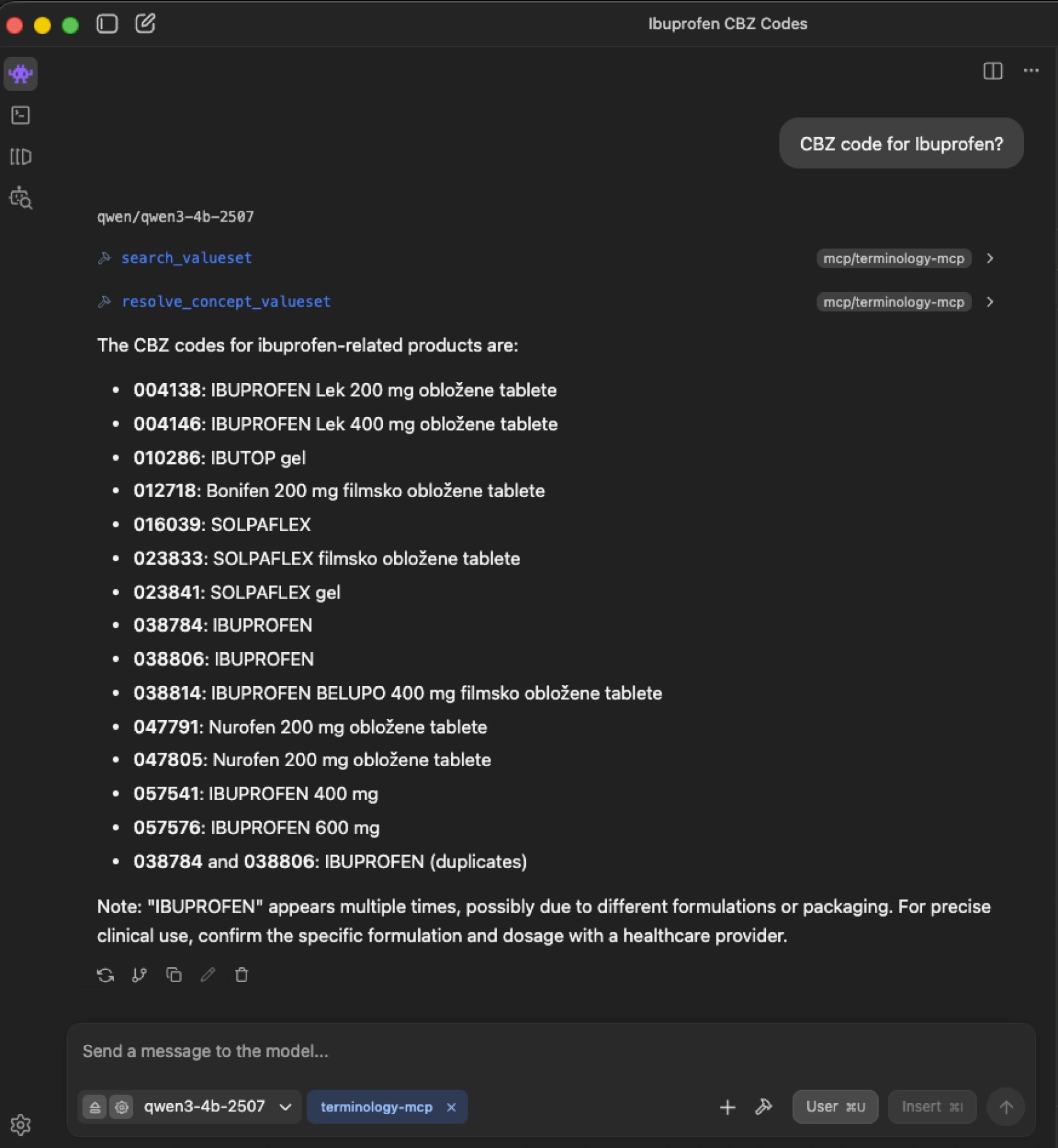
When asked “CBZ code for ibuprofen?”, the agent does not guess. It resolves the CBZ ValueSet and searches for matching concepts within it. The CBZ is the Slovenian national drug database – a terminology with no presence in public LLM training corpus. A generic model would either hallucinate a code or decline entirely. The grounded agent retrieves the authoritative result: multiple entries for different formulations and packagings of ibuprofen – each with its precise CBZ code – exactly as they exist in the terminology.
Querying SNOMED CT: pneumonia sub-concepts using ECL
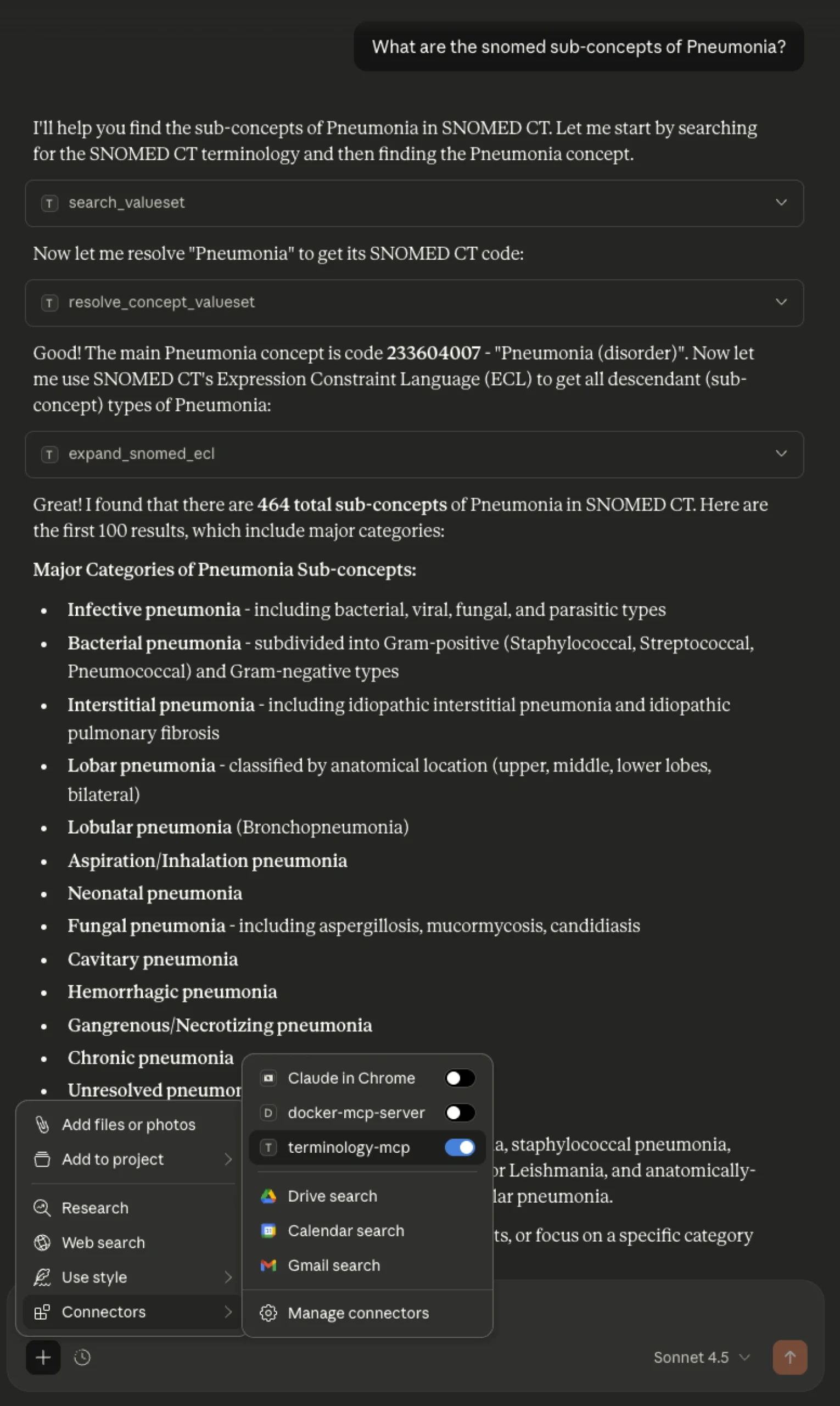
Not all code systems are simple lists. SNOMED CT is a full clinical ontology – a graph of interconnected concepts linked by typed relationships. To navigate it, SNOMED provides Expression Constraint Language (ECL), which allows querying by relationship type. Using ECL, the agent can retrieve all sub-types of a given concept – for example, every form of pneumonia classified under “Pneumonia (disorder)” – by executing the query against the FHIR Terminology Server rather than generating a list from model memory.
Validating a national code
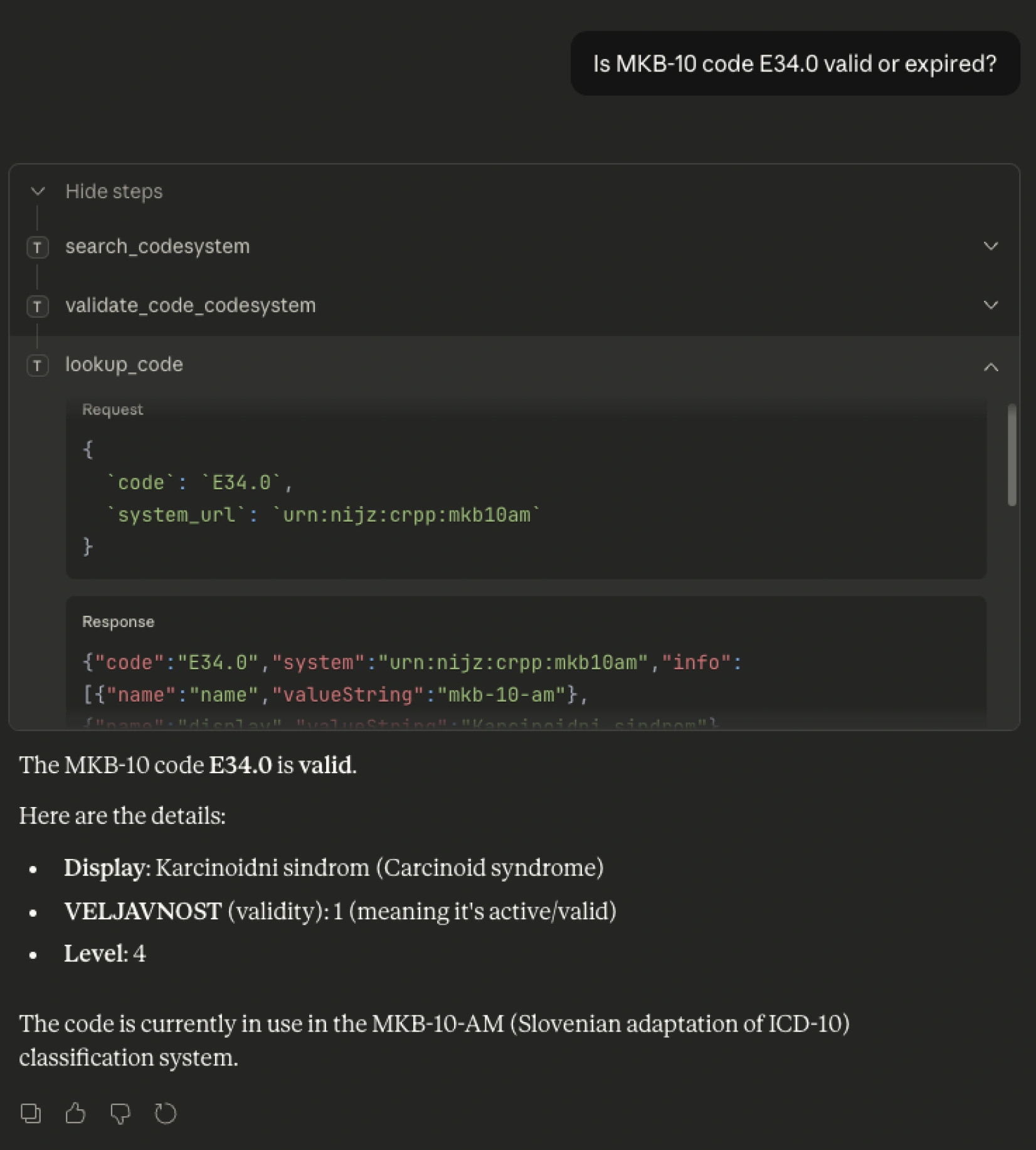
Validation is often more important than lookup. Clinical terminologies are living systems: SNOMED CT updates monthly, ICD-10 adaptations update annually. A model trained twelve months ago cannot know which codes are currently active. The MCP server always queries the configured FHIR Terminology Server – so as long as that server is current, every validation reflects the present state of the terminology, regardless of when the model was trained. The example below checks whether Slovenian MKB-10-AM code E34.0 is valid and active. The agent asks the server.
Why this matters?
The gains across these examples are architectural, not model-dependent. Grounding agents in authoritative terminology services produce several concrete improvements:
Correct and auditable answers: Every code is drawn from the authoritative source and traceable to a specific CodeSystem version. This is the kind of traceability that regulated healthcare environments require.
Transparent failure instead of silent hallucination: When no matching code exists or a submitted code is deprecated, the agent clearly states this. In clinical workflows, knowing that a match was not found is itself actionable information.
Flexibility in model choice, including local deployment: Because all terminology-specific capabilities reside in the MCP server, the agent needs no fine-tuning for clinical coding. This makes it practical to use smaller, locally hosted models in environments with data sovereignty requirements.
No vendor lock-in: The MCP server connects to any FHIR-compliant terminology server. Switching the underlying server updates the agent’s knowledge accordingly, with no dependency on a single data provider.
Accessible to non-FHIR experts: Clinicians and developers do not need to understand FHIR query syntax or ECL expressions. The agent handles that translation. The user asks a natural-language question; the agent returns a grounded answer.
Conclusion
Grounding AI agents in FHIR Terminology Services through MCP shifts the model’s role from a generator of answers to a source of truth. The intelligence is applied where it is strongest: understanding intent, navigating complexity, and coordinating the right operations. The facts themselves come from systems designed to hold them. This is a necessary step toward making AI usable in real clinical environments. Deterministic answers, clear failure modes, and full auditability are not optional features in healthcare, they are prerequisites.
As healthcare systems continue to adopt open standards like FHIR and invest in national and institutional terminology services, the opportunity is clear. By connecting AI to these authoritative sources through open protocols like MCP, we can move from impressive demonstrations to dependable tools. In the end, the question will not be whether AI can speak clinical language, but if it can do so with the precision and accountability that care demands.
To see how this approach fits into the wider healthcare data ecosystem, read more about the role of interoperability and open standards below.